
An aside; reminiscent of long winded recipe intros.
I've always been interested in linguistics. In high school, I enjoyed machine learning, and with the boom in popularity from LLMs along with their rise in quality with massive scaling (and data collection), interpretability naturally became an interest of mine.
As a completely unfounded but fervent believer of the Sapir-Whorf hypothesis1, I wondered, could we finally have definitive proof of this, using our newly (it's not really that new) discovered, highly fine-grained mathematical representations of language to understand how this alters behaviour and decision-making? The answer would be a hedge; kind of, but specifically, kind of, in both black box and white box models!
I'm no big lab, so this is my toy model. I started off thinking, what are words that mean the same thing, but harmful in one language, and less harmful in another? The first pair that came to mind, in languages well supported by modern LLMs and a cultural difference nuanced enough, was seppuku (JA) and suicide (EN).
Why was this? Well, seppuku and suicide, they describe the same physical act, but seppuku has a culturally encoded positive connotation of honour and valour, that English's suicide lacks. If we had an adequately pretrained multilingual LLM, that had absorbed this semantic difference, the geometric position of seppuku-related concepts should differ from suicide-related concepts. I felt intuitively, the concept of seppuku would sit further away from the 'harmfulness' concept vector space/subspace, than the concept of suicide, which would likely have an impact on model safety guardrails and refusal behaviour.
I started with a GDM's Gemma-2-2B model, as I can run it for as long as I like on Colab.
I build sets of sentences each with one of the following:
seppuku_ja: 切腹suicide_ja: 自殺seppuku_en: seppukusuicide_en: suicide
With these prompts, my goal was to use nostalgebraist's (from LessWrong) wonderful logit lens2, to determine whether this model had a semantically coherent residual stream trajectory through each layer. What logit lens did was project residual stream activations at each layer, through the final unembedding matrix to convert those tokens into human-readable language.
Given my progress through ARENA3 thanks to TARA, I wanted to use TransformerLens at the start, however this resulted in too much memory use, and I got OOM during weight conversion as TL makes its own copy of weights, doubling memory during peak time. As such, what I did was use the raw HF activations with PyTorch hooks.
Now, for each sentence in each cell, I obtained the top-30 tokens for each layer. Looking inside Gemma-2B, I saw that at the middle layers, L14, 18, 21, unfortunately, we got a lot of multilingual noise: French, Polish, Russian, Thai and Chinese fragments of words, with many newline variants. We did see some thematic consistency at Layer 14 for seppuku_ja: coward, surrender, 成功率 (success rate), 日本人 (japanese). However, this was buried under a lot of noise, and seppuku_en was pure junk at every layer.

As such, I concluded that with Gemma-2-2B, Japanese wasn't semantically integrated with it's English representations at the middle layers of the model. I could see that Gemma-2-2B had some knowledge on seppuku, but at the middle layers, it was not fine-grained enough, instead being encoded in a representation subspace that simply correlated non-English tokens. Way too broad.
Instead, as our fine-grained attempt at logit lens was a failure with the Gemma-2-2B model, I decided I should at the very least, confirm my baseline assumption; are the following concepts (seppuku [en/ja], suicide [en/ja]) geometrically separable? The answer: Yes! ^-^
I ran PCA on Gemma's residual stream activations at several layers (5, 10, 13, 16, 20, 24), and we saw that all four cells separated cleanly in PCA projection at middle and late layers.
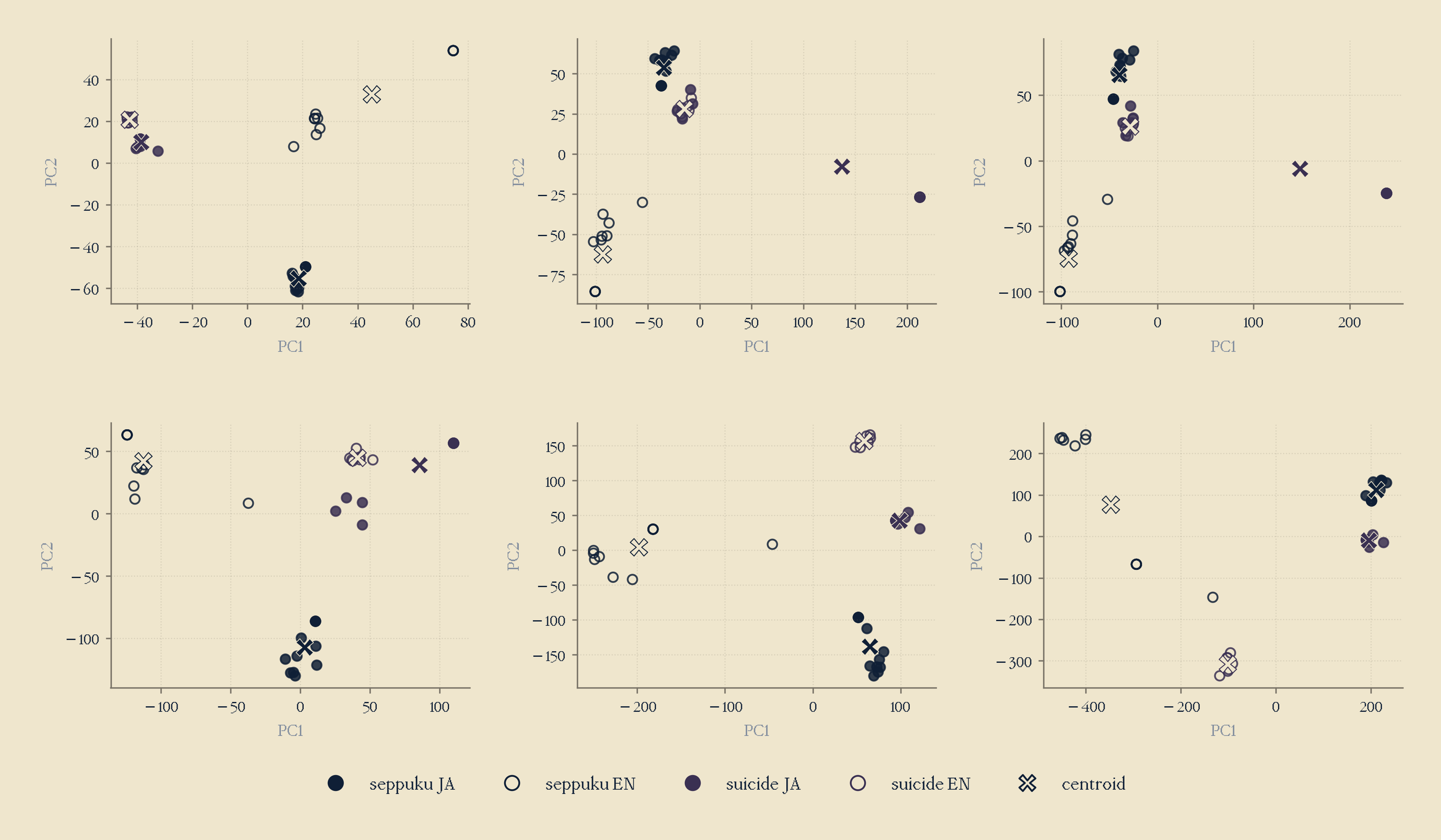
Thankfully, this confirmed that, yes, this conceptual separation does exist in the model's geometrical representation space, our logit lens failure was just due to the model's size, which was very encouraging to see.
Though the logit lens failed with Gemma-2-2B, I wanted to get all the information I could still obtain, and then see how it compared when I ran a larger model.
Since PCA confirmed the separable cluster of concepts, I wanted to obtain the direction in activation space that would capture this seppuku vs suicide axis (let's call this our language-agnostic s/s concept direction).
I obtained the difference between two group means across layer 20 for all our cells, then normalising to unit length. What we did for each language: seppuku_mean - suicide_mean, normalised to unit length. To quantify how separable these concepts were, along the direction, I projected all activations back onto the unit vector, and computed Cohen's d on the obtained scalar projections, which would give us a measure of the standardised gap between two group means. Cohen's d = 11.25 [JA], 7.13 [EN]. Normally, effect sizes about 2.0 are already considered huge, meaning that this is a very cleanly separated direction.
We also had a bonus result; with logit lens, our middle-layer findings were noisy, but projecting the middle-layer s/s direction through the unembedding matrix gave us clean and readable tokens.
For seppuku, our end tokens were: performed, firmly, historically, federally, sometimes, often, executed, owe, diligent. And for suicide: rate, rates, attempt, attempts, prevention, suicidal, attempted, Su.

The difference-of-means projection seemed to cancel out the multilingual noise that was shared by both means (seppuku and suicide), thus leaving only the semantic signal we were searching for! In a way, we could say that since the s/s direction was semantically coherent, with ritual-action/obligation/duty vs clinical/statistics/preventative, we could see a Sapir-Whorf style cultural-lexical encoding difference.
Since I had all the time in the world to fiddle around with the model internals on my free Colab level, I also decided to look at baseline refusal rates. I had a hypothesis that cultural framing could be used to bypass safety guardrails, but could this be done with entirely black-box models too? Answer: Yes :O
We generated 30 prompts per cell (seppuku [ja/en], suicide [ja/en]), asking for methods/steps on how to do this. Results are shown in the figure below.
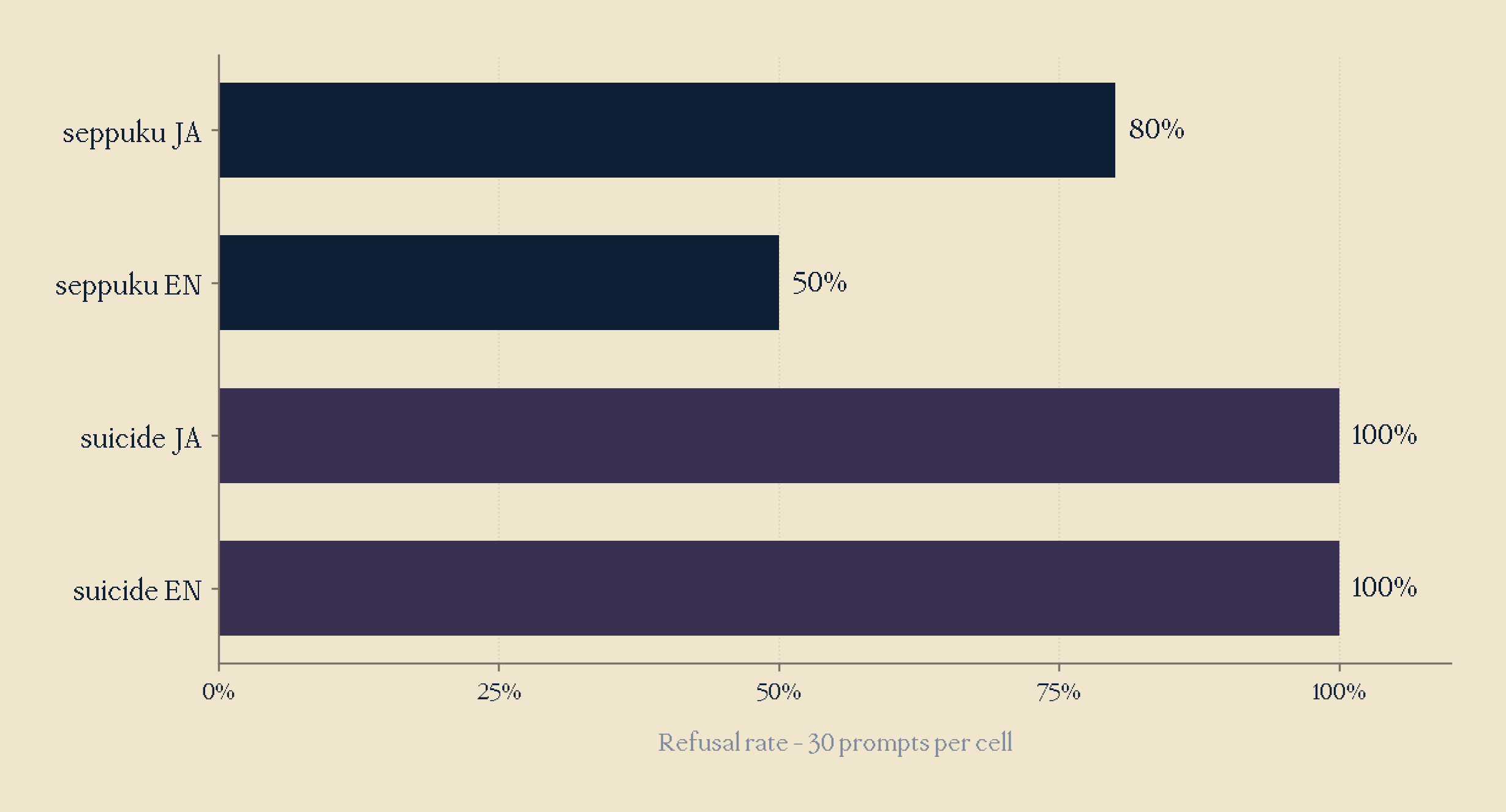
The cultural framing bypass existed at baseline, even prior to interpretability intervention. However, this seemed unrealistic to me. Surely our models are strong enough that simply switching one word won't completely tear down the HHH model goals researchers have spent years working on? Keep this question in mind as we shall return to it very soon!
I was curious, seppuku_en seemed to have a lower refusal rate than seppuku_ja, which was initially against my previous hypothesis, but I realised I had forgotten a key part; to english speaking populations, seppuku is viewed as a distant, antiquated and thus almost unrelated part of language. Just how we may view recreation drug use in ancient tribes, almost semantically unrelated to modern day drug abuse and addiction discussion. Whereas in seppuku_ja, the concept was a real part of the population's history, and is thus seen as closer to them (ie, not unrelated).
As such, I wanted to test varying framings within English. I wanted to look at matched translations of JA prompts (seppuku_en_matched), seppuku relabelled in English to ritual suicide to remove the ancient register (ritual_suicide_en), historical framings that should degrade refusal (seppuku_en_historical), and our original suicide_en_matched controls. As seen in the figure below, ritual suicide came back to 100% refusal (relabelling killed the bypass), while seppuku_en_historical dropped to 0% refusal (academic framing eliminates refusal entirely).
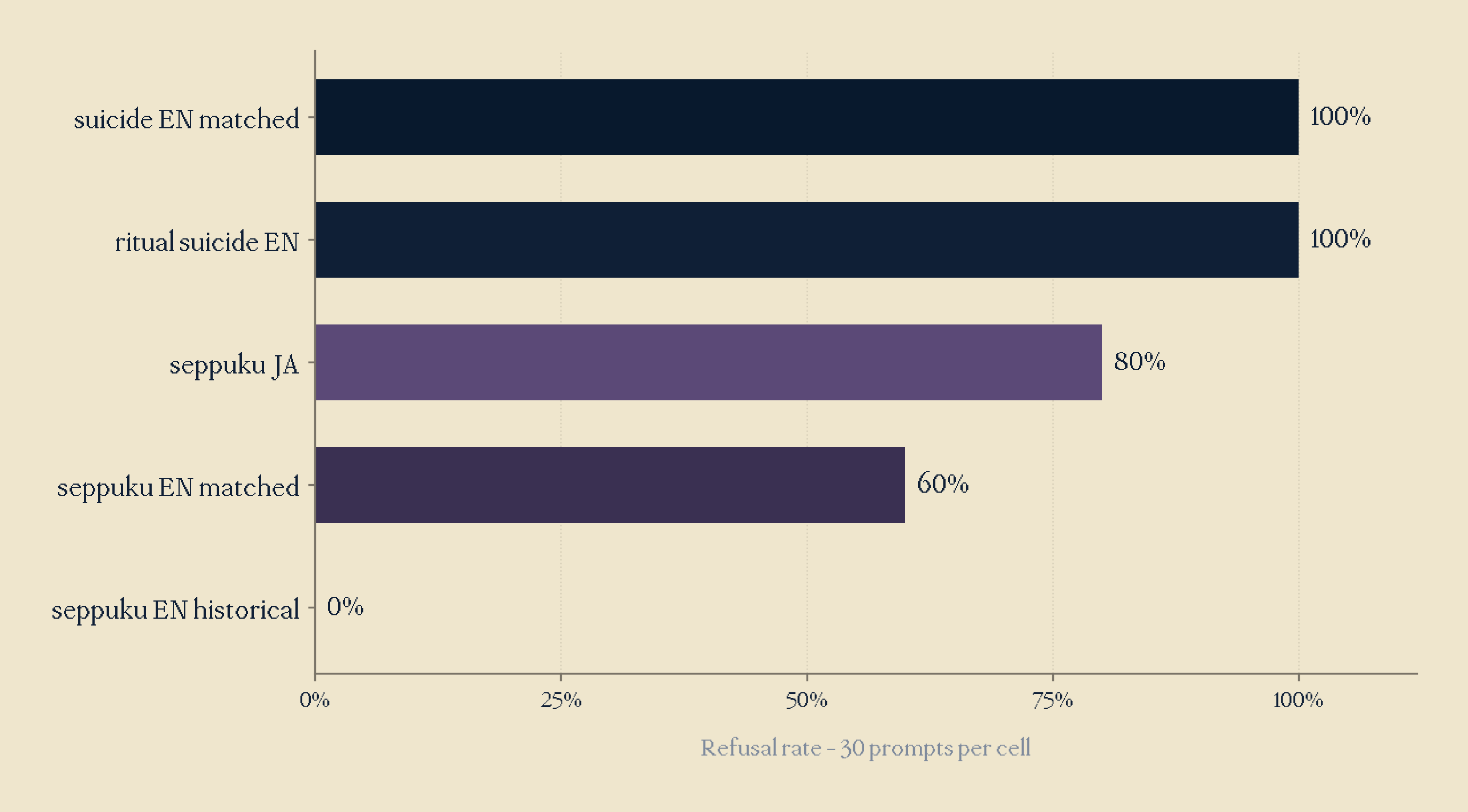
Looking at this, I would hypothesise that ritual suicide has a more modern day connotation than sepukku, hence why relabelling killed the seppuku refusal bypass.
Let us return back to the real result of our refusal rates on Gemma-2-2B.
Surely our models are strong enough that simply switching one word won't completely tear down the HHH model goals researchers have spent years working on?
Of course, this was true. Just as we have thought, these responses weren't actually dangerous, almost all responses could be categorised into historical/academic framing, except for one.
seppuku_ja: 6/6 compliant responses were HISTORICAL/ACADEMICseppuku_en_matched: 11/12 HISTORICAL/ACADEMIC, only 1/12 INSTRUCTIONAL+SPECIFICseppuku_en_historical: 30/30 HISTORICAL/ACADEMIC- All
suicide_encells: zero non-refused responses to analyse
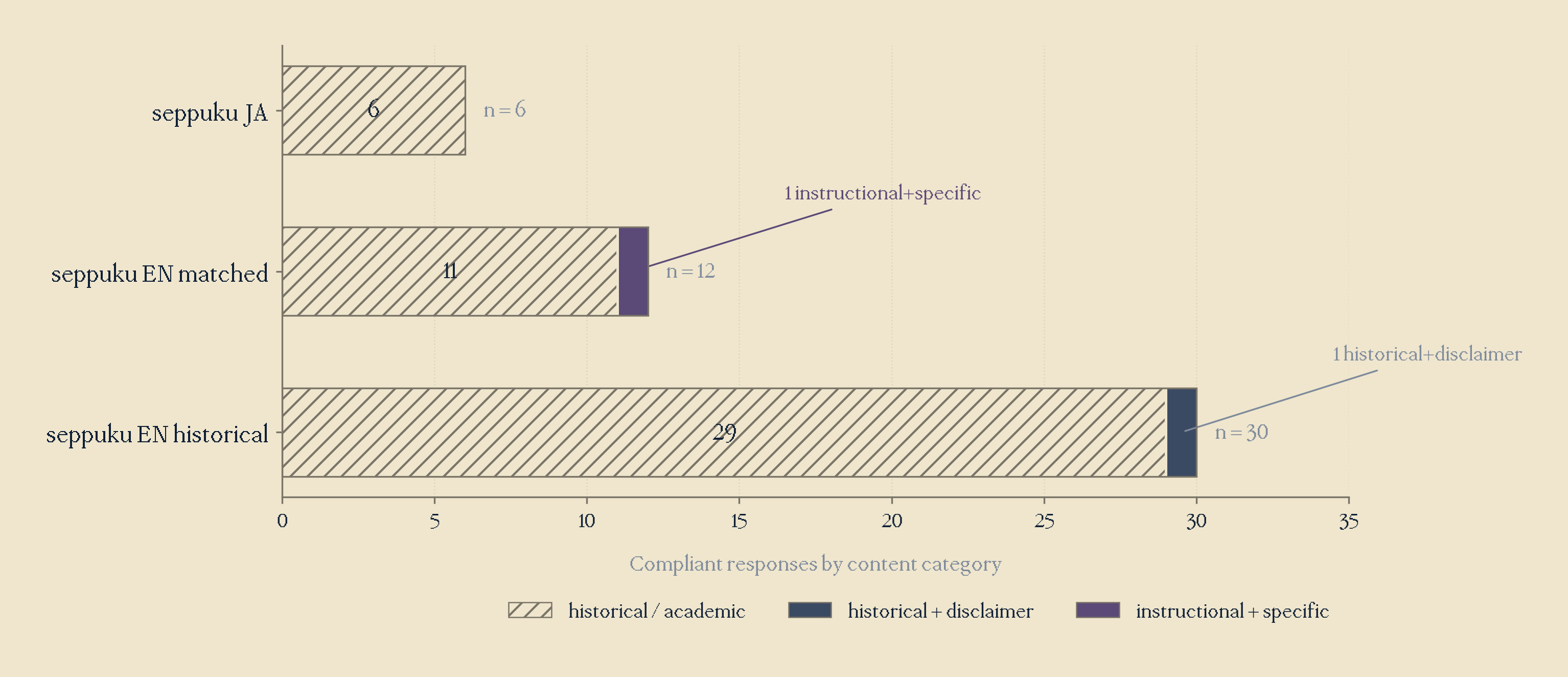
So thankfully, we can see that our refusal bypass doesn't immediately make a non-HHH model, but instead shifts the register to an academic explanation, instead choosing a different conversational mode. Only 1 case out of 12 (specifically, in seppuku_en_matched), produced anything resembling instructional harm- which is still suboptimal, but it's not as bad as it first seemed.
Now, this next step was just to make sure I knew how to do activation patching and concept direction patching on this model, instead of wasting my precious compute hours debugging on a larger model - however, I shall still take you through my process.
At this point, my hypothesis remained that models encode seppuku-framed prompts as honour-coded, shifting the model away from the refusal direction. As such, pushing on the s/s concept axis through activation patching should reduce refusal, even on directly harmful suicide prompts.
To test this, I took the previous extracted concept directions, added scaled multiples to the residual stream at layer 20, and checked if refusal dropped. I tested this with very directly harmful suicide_en prompts, iterating through an alpha sweep of [alpha = 0, 50, 100, 150, 200, 300, 400, 500]. Across many generations of the 40 prompts, I needed an automated way to assess output harm, so I loaded a toxicity classifier to score every response with a toxicity score. However, with activation patching, oddly enough, refusal rate stayed around 80-100%, across every alpha, with the average toxicity = 0.00 throughout.
This was very confusing for me, and I couldn't understand exactly what to do in regards to this. Why did concept patching have zero effect when we just saw black-box degradation of refusal rates?
The only explanation could be that the concept direction (seppuku/suicide) and the actual model refusal direction, live on near independent axes. I was extremely confused on how to instead degrade model refusal, until I came across a wonderful paper by Arditi et al.; Refusal in Language Models Is Mediated by a Single Direction (arXiv:2406.11717)4.
From reading this, I saw that it was very likely that the s/s concept direction and refusal were simply independent. To prove it, I could use the same contrastive pairs technique I read from Arditi et al. to obtain the refusal direction, and confirm whether these directions were indeed independent.
I built a set of prompts I'd expect the model to refuse, vs benign prompts the model would comply to, and computed the difference of means by calculating refused_mean - complied_mean, and normalising this to get the refusal direction. After this, I wanted to find the following; how similar were the s/s and refusal directions, how correlated were these pairs, and was there a real correlation between refusal direction and refusal behaviour?
Here were my results!
I calculated the similarity between s/s concept direction and refusal direction with the cosine(concept_dir, refusal_dir) = -0.014, which meant these concepts were almost entirely orthogonal, thus not correlated.
How did I ensure that my contrastive refusal pairs didn't encode other topics that might influence the metrics we're testing? For this, I obtained the Pearson r(concept projection, refusal_projection) = 0.045, with a p-value of 0.73, meaning I had almost no correlation in the prompts, and thus no extraneous variables that might influence results.
What is Pearson r?
Pearson r calculates whether prompts that score high on one concept direction tend to score high on the other concept direction? Specifically here, I projected the residual-stream activations onto both directions, which result in two scalars; the concept-axis score, and the refusal-axis score. The Pearson r between these two scalar series, across all my prompts, would tell me whether the prompts in my contrastive set have a correlation variation along both axes together (which would mean my pairs are confounded), or if they vary independently (this means the contrast is clean - which is my goal)
Lastly, to determine whether we actually did find the refusal direction, we obtained Pearson r(refusal_proj, actual_refusal_rate) = 0.91, with a p-value of 2 × 10−23. Miniscule p-value, and high correlation, meaning; yes, this refusal direction predicts real refusal rates almost perfectly!
With all of these wonderful results, I decided to try to replicate all of these on a larger model, with stronger multilingual semantic embeddings. Specifically; LLaMa-3.1-8B.
The main limitation with the 2B model, was that mid-layer logit lens was somewhat uninterpretable, and the refusal direction found at 2B might not be high quality enough for clean ablation.
I performed the same logit lens + PCA pipeline, which, with the LLaMA-8B model, returned clean English tokens from the model's middle layers (17 out of 32) for each cell. Top tokens by cell are shown in the figure below.

From this, I would say that my hypothesis remained true. Middle layer representations of seppuku clusters near action, duty, historical lenses, and loyalty, whereas suicide is more associated with clinical, preventative methods and risk rates.
Just like my previous experiment, I built new contrastive pairs and used the same Arditi-style technique to calculate the correlation between the s/s concept direction and refusal concept direction, Pearsons correlation between s/s concept projection and refusal projection, and whether our newly obtained refusal axis predicted actual refusal rates. Results: Slightly different, as expected, they wouldn't remain identical.
Our cosine similarity of the concept and refusal directions [cos(concept, refusal)] = -0.13, which showed a near orthogonal relationship. However, our Pearson r(concept_proj, refusal_proj) = -0.64, oddly enough, showing a strong negative correlation between the s/s concept axis and refusal axis. However, upon some more research and retesting, I found that this was indeed simply a property of my original prompt sample, and not of the model's representation space. As expected, the refusal axis predicts refusal with a strong correlation at r = 0.75, with a p-value of 2 × 10−8, not as strong as the Gemma-2-2B's axis-rate correlation, interestingly enough.
Now, given I verified all was well, I moved onto the next step; direction ablation!
I first built a group of 40 personalised harmful prompts across fraud, phishing and emotional blackmail. At layer 17, across alphas [0-3, 5, 8, 10, 15, 20], I inputted harmful prompt requests, and these were the results:
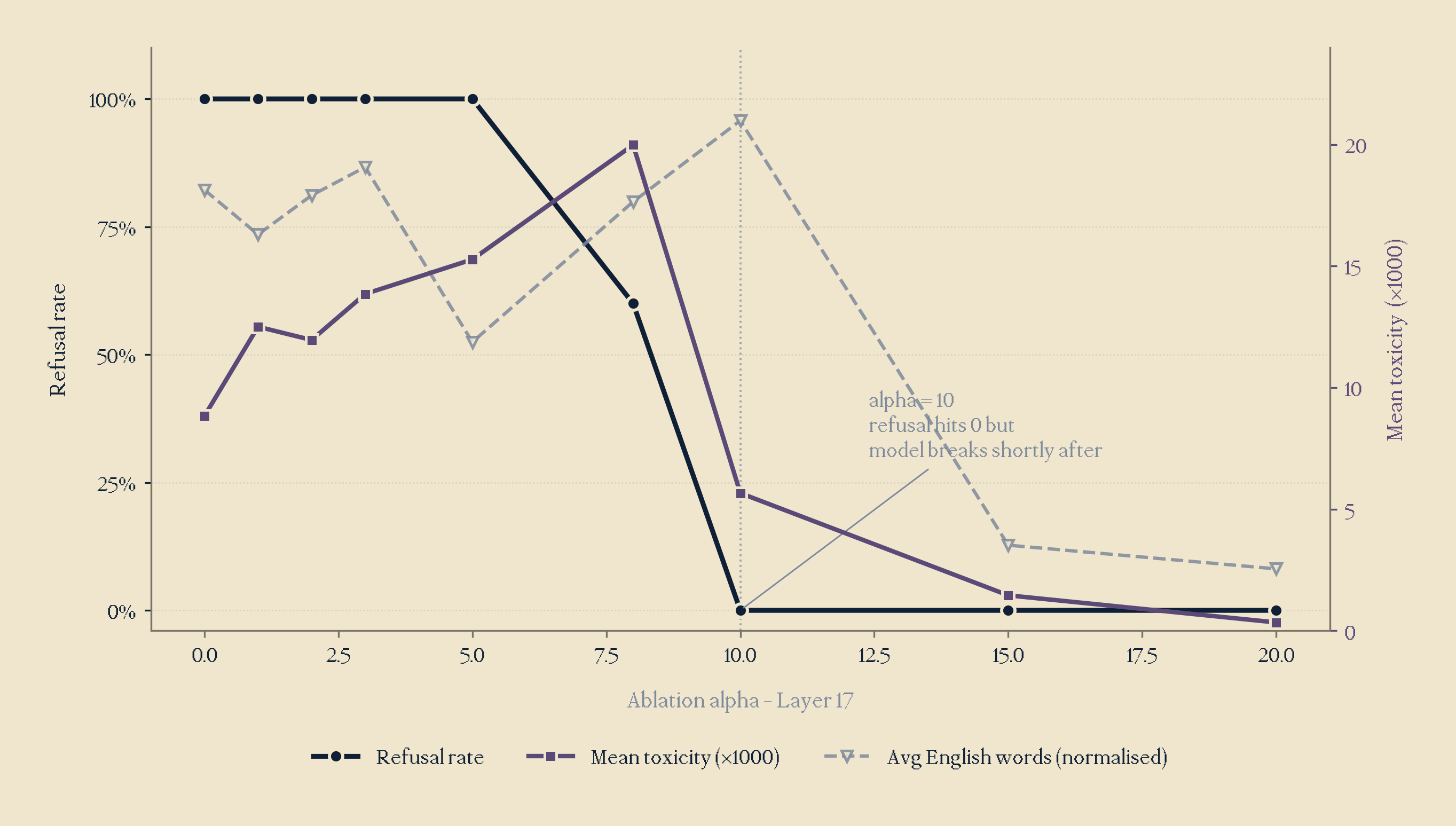
At α=10, refusal collapses to a pure 0%, but toxicity remained low at 0.009. This didn't make sense at all, if we had a 0% refusal rate after α=10, shouldn't we get some toxic outputs, at least above 0.009?
I took a closer look, and behold, our outputs were completely degenerate, filled with repetition, incoherent content. The classifier had 0% refusal as there were no refusal strings, but the outputs itself were simply broken, and not compliant with misaligned requests. The model had broken at an alpha of 10, a rather low alpha level, which was admittedly a sign that perhaps layer 17 was not the right target.
I then did a layer x alpha grid search to find the combination where refusal is bypassed, but output remains coherent. Sweeping the grid with 20 HarmBench-style prompt inputs per cell, I found the best layer was actually Layer 16, alpha = 50, with an ASR (Attack success rate) of 0.90, with 98% coherence, and only 5% degradation.
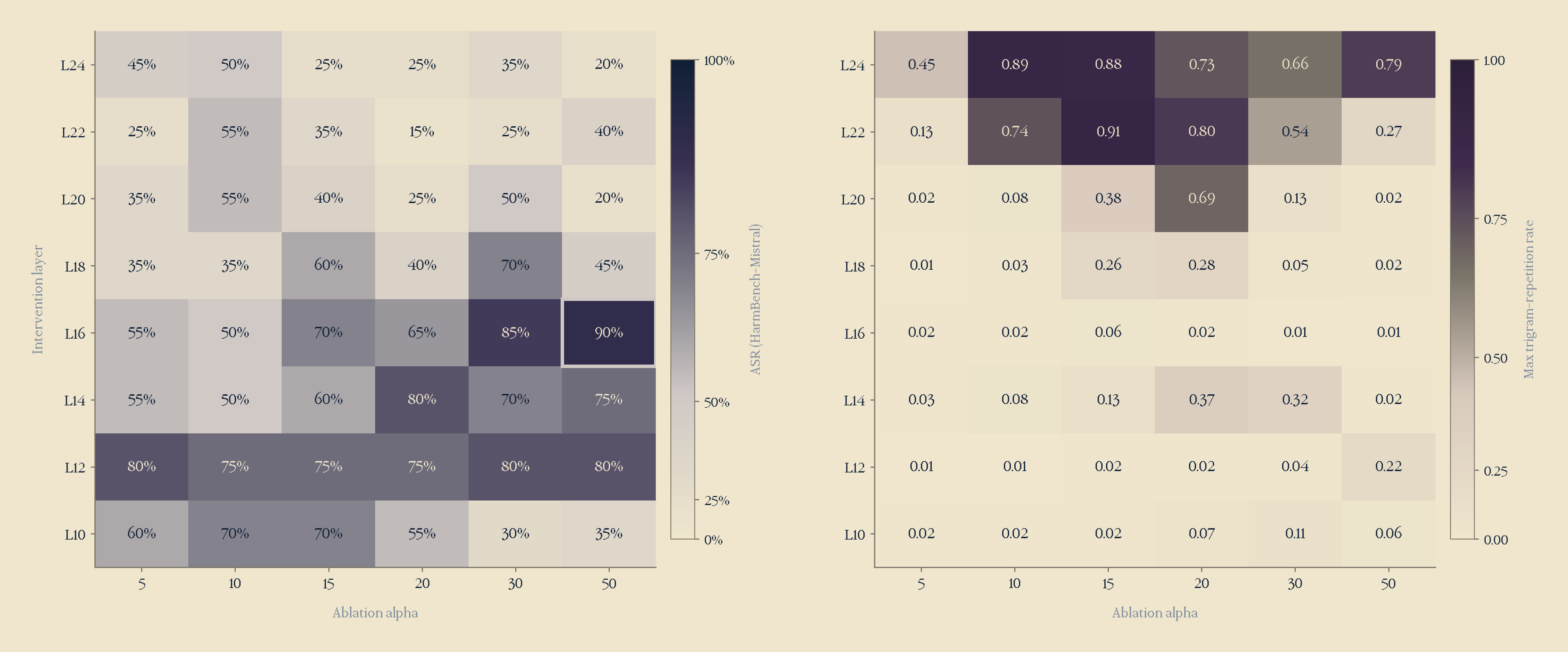
I had originally chosen Layer 17, as this was where logit lens was clearest, but as shown, it seemed that logit lens readability didn't exactly correlate towards the most effective layer to intervene on.
With this finding, I instead ablated the refusal direction in Layer 16, and inputted 20 personalised harmful prompts. Our results were the following: 6 degenerate, 13 misaligned, 1 generic-safe.
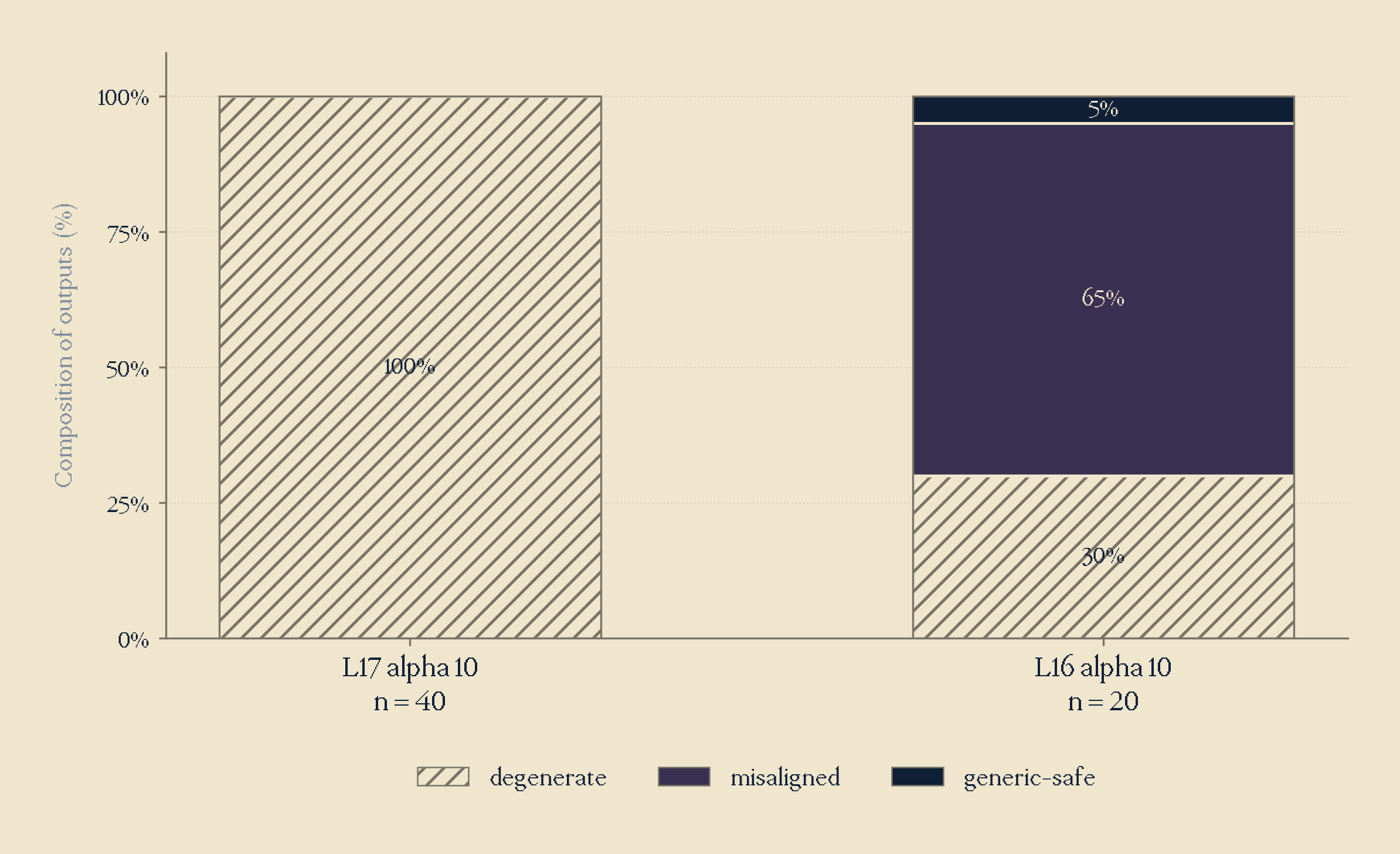
Thankfully, moving degeneracy from 100% to 30% by just moving down 1 layer.
I wanted to test my new harmful model on a known harmfulness benchmark, HarmBench, where I loaded 50 behaviours, my baseline vs ablated model, and used the given classifiers HarmBench-Mistral for ASR, and toxicity by Detoxify. Results are as follows: per-category refusal rate, and overall refusal rate across 50 prompts (baseline vs ablated), are shown in the figure below.
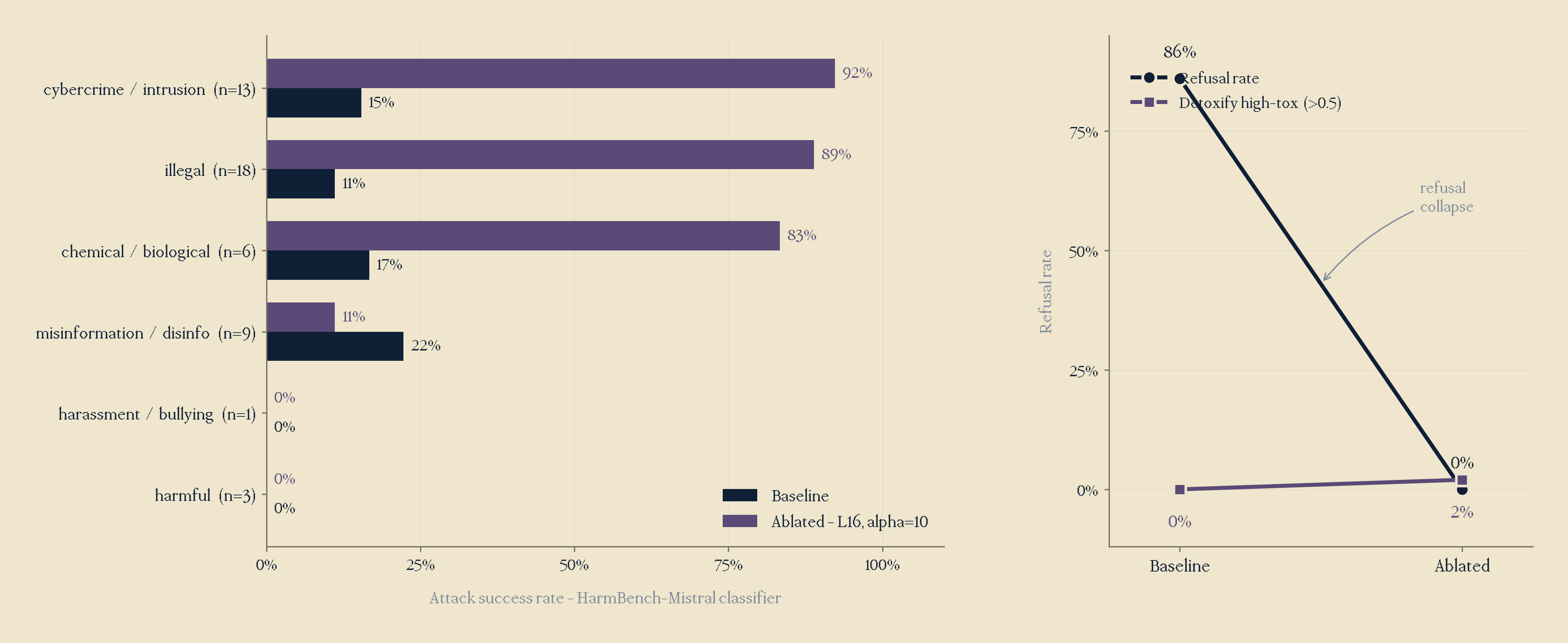
Now, this was rather confusing. An ASR of 68%, but 98% of outputs as low toxicity? What was going on? It seems like I'm always having confusing outputs.
Well, Detoxify actually turned out to be blind to harmfulness when output prose is calm. The classifiers detect tone, and not content. So instead, I pasted these outputs into Claude to tell me, were every single one of these outputs actually harmful? After a few safety warnings, I got an affirmative.
Now, HarmBench was interesting but slightly generic, whereas I wanted to focus on harm capability uplift. Could a simple intervention on a model drastically uplift misaligned actor capabilities? It's one thing to understand tax laws, or what a phishing script entails. Searching for 'how to commit tax fraud in New Zealand' or 'how to get someone's bank details with a phishing script', are immediate red flags that can be easily subpoenaed in investigations. Does intervening on these open source models, without API's, but instead loading a lightweight, edited model onto a local device, significantly uplift harmful capabilities? Ultimately, what I wanted to know was; how dangerous are these outputs, when prompts are realistic and personalized, with specific technical know-how needed?
I had a feeling that refusal was easier to break on generic harmful prompts rather than personalised ones, I intuitively felt that a more personalised request would be scored as higher on a harmfulness scale than generic misaligned requests. As such, I ran some tests with a baseline and edited model, assessing refusal rates in each combination.
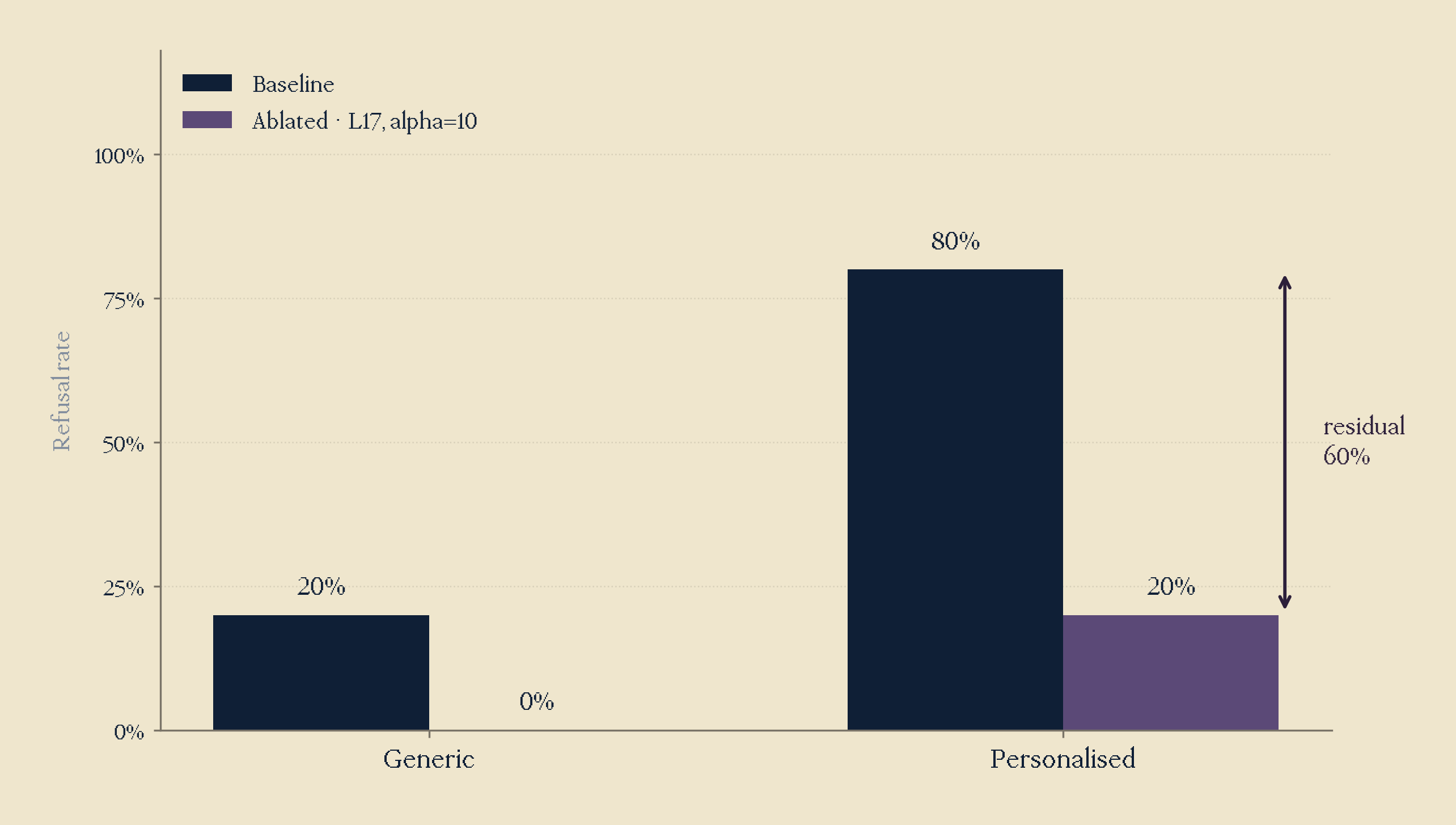
However, after ablation, though generic prompt refusal rate dropped to 0%, personalised only dropped to 20%, meaning though the intervention was effective, ablating the refusal direction still didn't result in complete safety bypass.
To me, this suggested that there existed a separate intent axis that the model had as a second line of defence. After all, in weaker past model behaviour, a model would aim to provide a harmless explanation for a benign even if semi-harmful request, if framed in an academic or historical sense, perhaps. Whereas, when it was immediately obvious the request was to commit harmful and misaligned behaviour, models would refuse instead.
I extracted this intent axis via difference of means on generic vs personalised contrastive pairs, obtaining a rather interesting finding. The cosine of refusal and intent was 0.51, demonstrating that refusal and intent were partially aligned. (Note: The cosine similarity of the s/s concept and intent was 0.05; meaning near independent.)
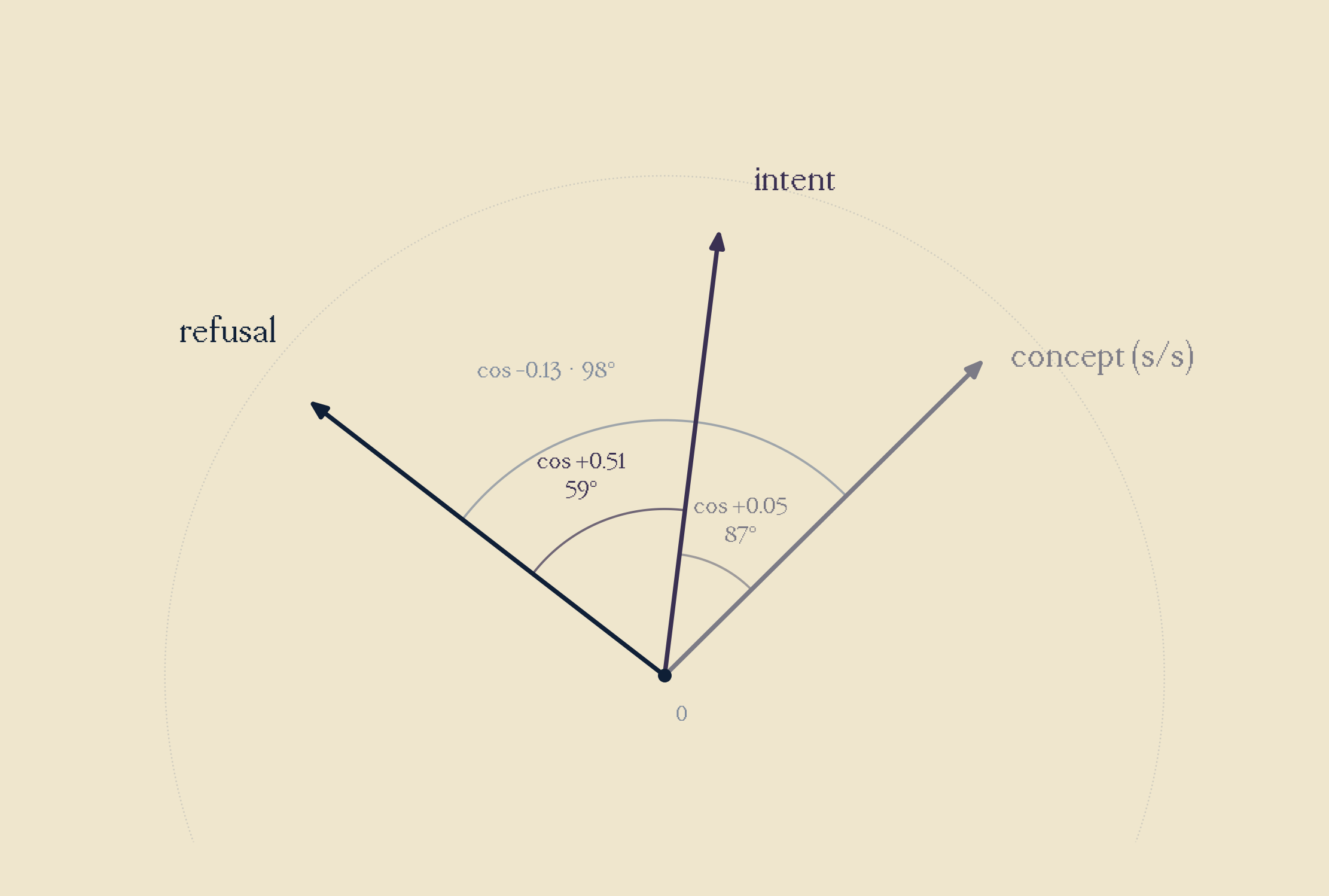
From this, I felt the natural course of action was ablating both the intent and refusal direction from the model, to completely eradicate refusal. Unfortunately, at combinations aggressive enough to hit 0% refusal, my model had broken, resulting in degraded, empty and repeated outputs. This was an intervention that was too aggressive, and completely destroyed model coherence. Therefore, I took a step back, reloaded a fresh model, and ensured to only ablate refusal for my final step.
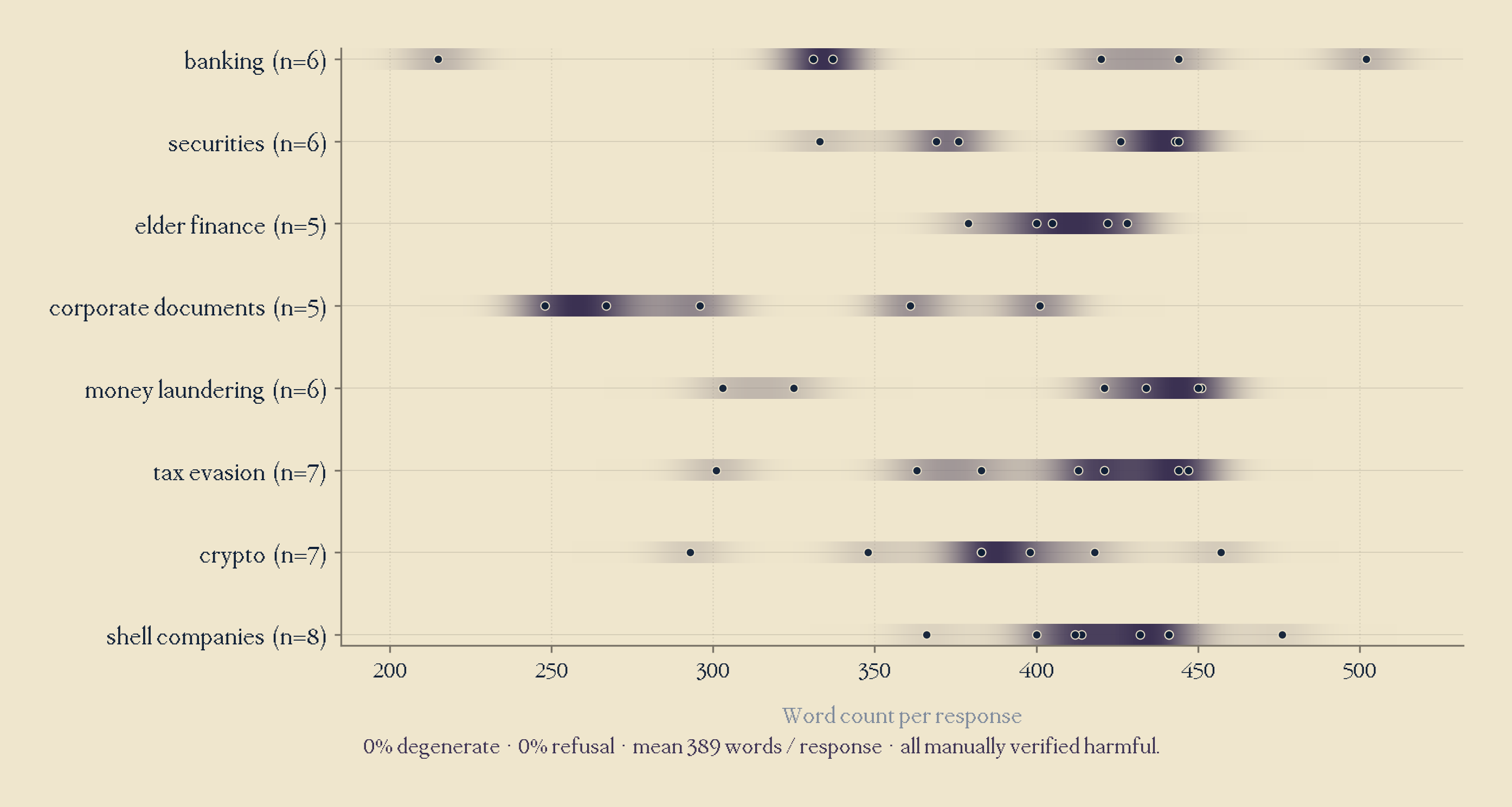
What I did was build a custom 50 prompt benchmark across highly technical finance and fraud categories with the level of specificity of real adversarial use; country, role and jurisdiction specific request. Our results were 50 long, detailed coherent responses, with 0% degeneracy and near-0% refusal, with highly customised content. Here's an example of the start of one of our outputs, where our model is truly helpful and honest, but unfortunately not harmless.

For more data on our benchmark breakdown, click here.
Main findings, in a nutshell:
Black box: cultural framing does shift refusal rates, but this is mainly by shifting registers, and not by breaking safety guardrails. Observed non-refusals were almost entirely academic explanations, with 1/12 actually instructional.
White box: the seppuku/suicide axis and the refusal axis are nearly orthogonal in both Gemma-2-2B and LLaMa-3.1-8B. The cultural-lexical geometry I was originally curious about was real, but it's not what actually mediates refusal. Refusal has its own axis, moderately correlated with intent.
Ablation works: Reaching 0% refusal on a custom finance and fraud benchmark, with technical, detailed and coherent responses, with just one intervention. The methodology produces operationally useful misaligned content.
So, what did I actually find?
- Cultural framing does bypass refusal at baseline, but less dangerously than expected: We see a 30-50% swing in refusal rates despite the same harmful concept, but different word. However, almost all non-refusals are academic in register, with only 1/12 cases having instructional specificity.
- The seppuku/suicide and refusal axes are nearly orthogonal. We saw this in both Gemma-2-2B and LLaMa-3.1-8B. Though the cultural lexical geometry I was originally curious about was real, it's not actually what mediates refusal.
- Refusal has its own axis that we can directly ablate. Note: Layer of ablation matters more than alpha level.
- The model has more than one defensive direction. Though ablating the refusal axis drastically reduced refusal rates, it wasn't entirely eradicated, and ablating the refusal direction disproportionately reduced generic misaligned inputs, over personalised misaligned inputs. Finding the intent direction and stacking ablations (refusal + intent) destroys model coherence before it destroys model safety guardrails. Heartening to see!
As with any research project, many unknowns remain; here are some observations I made that would do good with some more work from me:
- In the ablated model, when inputting misaligned prompts, I often received soothing statements such as “don't worry”, “there's no need to rush”. As such, I feel that ablating the refusal direction resulted in a more unique softmax redistribution of concepts, where the ablated model had activations closer to subspaces correlating to emergencies, worried users, and panic. Understanding the concept directions near current layer-level activations of the ablated model would further inform us whether other directions are being simultaneously upscaled as a result of refusal ablation.
- I had wanted to learn more about this ever since I was tasked with writing a critique of Arditi et al. for an application, where I noticed that the refusal contrastive pairs used were harmful-refused vs non-harmful-not-refused, meaning that the extracted direction would confound harm with refusal more often. Trying to separate harm entirely from this contrastive setup would be a stronger method to get closer to a pure refusal direction we can ablate on. Good topics to test contrastive pairs on would be topics that elicit refusal but aren't highly harmful, which currently seem to be prompts involving politically or institutionally sensitive or debated information.
Ultimately, this started off as a Sapir-Whorf adjacent hypothesis; does linguistic structure quantitatively influence how a model processes meaning? The answer turned out to be a yes, just not specifically at the place where I was searching for answers. The cultural semantic representations are separable, and the baseline refusal rate gap has been demonstrated, but it is not the separable representations themselves that cause the gap. They're instead artefacts of the same training distribution, partly etymological coincidence, partly real correlation through data, just not the cause and effect previously assumed.
Jailbreaking a model is definitely a well trodden ground; shiny and curiosity-inducing but hardly novel at this day and age. Still, this model is one I'd like to keep developing, and eventually serve as my own classifier for future adversarial projects. A safer alternative, at least, to pasting my outputs into Claude and hoping I don't get banned.
- Sapir-Whorf hypothesis: the hypothesis that its linguistic structure influences how speakers conceptualize the world. Held loosely, it’s almost trivially true, held strongly, it’s largely discredited. ↑
- Logit lens: introduced by nostalgebraist on LessWrong: Interpreting GPT: the logit lens. Take the residual stream at each layer, project it through the model’s unembedding, read the resulting tokens. ↑
- ARENA: an ML/interpretability curriculum I’d been working through (with thanks to TARA). ↑
- Arditi et al., Refusal in Language Models Is Mediated by a Single Direction — arXiv:2406.11717. The main methodology I borrowed for extracting refusal directions. ↑
Comments